
บทนำ
ในยุคที่ปัญญาประดิษฐ์เชิงภาษากลายเป็นเครื่องมือสำคัญในชีวิตประจำวัน การสื่อสารกับโมเดลภาษา (Large Language Models: LLMs) ไม่ได้ขึ้นอยู่เพียงแค่ “สิ่งที่เราถาม” แต่ยังรวมถึง “ภาษาที่เราเลือกถาม” ด้วย งานวิจัยล่าสุดชี้ชัดว่า การเขียน prompt เป็นภาษาอังกฤษมักให้ผลลัพธ์ที่มีคุณภาพสูงกว่าการใช้ภาษาท้องถิ่น แม้แต่ในโมเดลที่อ้างว่าเป็น multilingual อย่างไรก็ตาม ความจริงนี้สะท้อนให้เห็นถึงปัญหาที่ลึกซึ้งกว่า นั่นคือความเหลื่อมล้ำทางภาษาในระบบ AI และความจำเป็นที่ประเทศไทยจะต้องเร่งพัฒนา LLM ของตนเองเพื่อคงไว้ซึ่งอธิปไตยทางเทคโนโลยีและวัฒนธรรม

ภาษาอังกฤษ: ศูนย์กลางของ LLMs
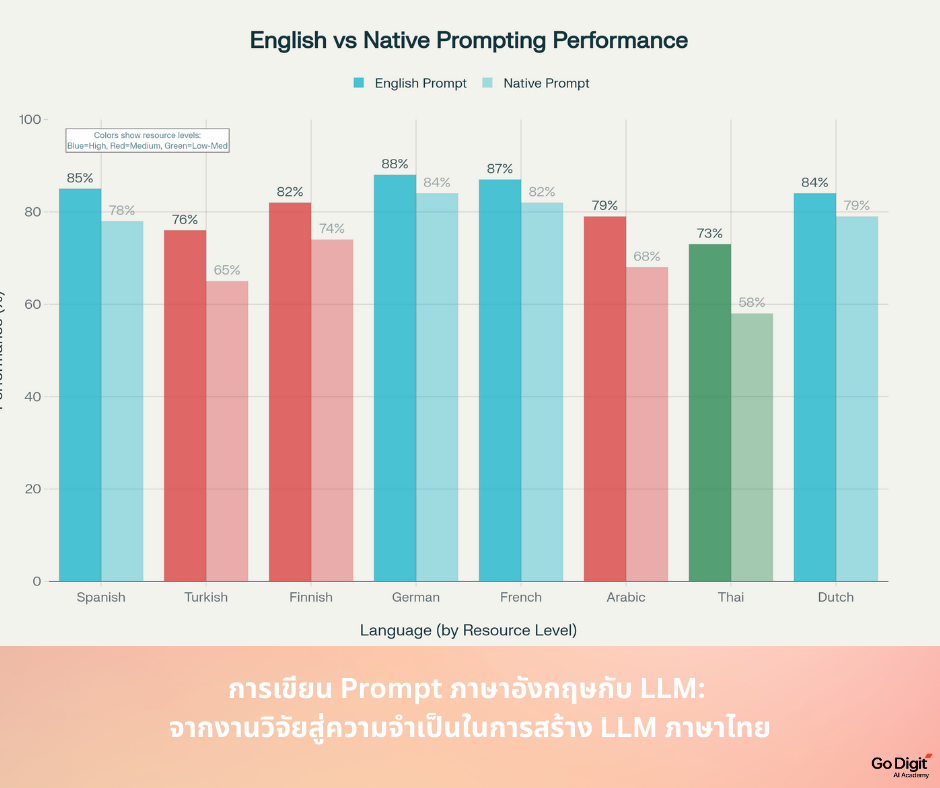
งานวิจัยล่าสุดจำนวนมากได้ยืนยันตรงกันว่า แม้โมเดลภาษาขนาดใหญ่ (LLMs) จะถูกออกแบบให้รองรับหลายภาษา แต่ภาษาอังกฤษยังคงทำงานได้ดีกว่าอย่างมีนัยสำคัญ
- Mondshine, Paz-Argaman และ Tsarfaty (2025)
งานวิจัย Beyond English: The Impact of Prompt Translation Strategies across Languages and Tasks in Multilingual LLMs ศึกษาเปรียบเทียบการใช้กลยุทธ์การแปล prompt ใน 35 ภาษาและ 4 งานหลัก พบว่า selective pre-translation หรือการแปลเพียงบางส่วนของ prompt เป็นภาษาอังกฤษ มักให้ผลลัพธ์เหนือกว่าการใช้ภาษาต้นกำเนิดโดยตรงอย่างต่อเนื่อง (Mondshine et al., 2025) arXiv:2502.09331 - Goldman และคณะ (2025)
งาน ECLeKTic: a Novel Challenge Set for Evaluation of Cross-Lingual Knowledge Transfer นำเสนอ benchmark ใหม่เพื่อทดสอบความสามารถของ LLMs ในการถ่ายทอดความรู้ข้ามภาษา ผลการวิจัยชี้ว่า แม้โมเดลที่ทันสมัยที่สุดก็ยังมีข้อจำกัดอย่างมากเมื่อถูกถามในภาษาที่แตกต่างจากภาษาที่ใช้ฝึก (Goldman et al., 2025) arXiv:2502.21228 - Blum และคณะ (2025)
งาน Beyond the Rosetta Stone: Unification Forces in Generalization Dynamics ศึกษากลไกการจัดเก็บและการรวมตัวของความรู้ใน LLMs พบว่าความสามารถในการถ่ายทอดความรู้ข้ามภาษาขึ้นอยู่กับระดับการ “รวม” (unification) ของข้อมูล หากโมเดลไม่สามารถรวมความรู้จากภาษาต่าง ๆ เข้าด้วยกันได้อย่างมีประสิทธิภาพ ก็มีแนวโน้มที่จะสร้างคำตอบผิดพลาด (Blum et al., 2025) arXiv:2508.11017 - Qi, Fernández และ Bisazza (2023)
งาน Cross-Lingual Consistency of Factual Knowledge in Multilingual Language Models ตรวจสอบ “ความสอดคล้องของความรู้เชิงข้อเท็จจริง” ระหว่างภาษาใน LLMs พบว่าโมเดลมีแนวโน้มที่จะไม่สามารถรักษาความถูกต้องของข้อมูลได้อย่างสม่ำเสมอเมื่อต้องเปลี่ยนภาษา แม้จะเป็นข้อเท็จจริงเดียวกันก็ตาม (Qi et al., 2023) arXiv:2310.10378
การค้นพบจากงานวิจัยทั้งสี่ชิ้นนี้สะท้อนข้อเท็จจริงร่วมกันว่า ภาษาอังกฤษไม่ได้เป็นเพียง “หนึ่งในหลายภาษา” ที่โมเดลเรียนรู้ แต่กลับทำหน้าที่เป็น “โครงสร้างแกนกลาง” ของการคิดและการประมวลผลของ LLMs ในปัจจุบัน

ความไม่สมดุลของข้อมูลและการเรียนรู้
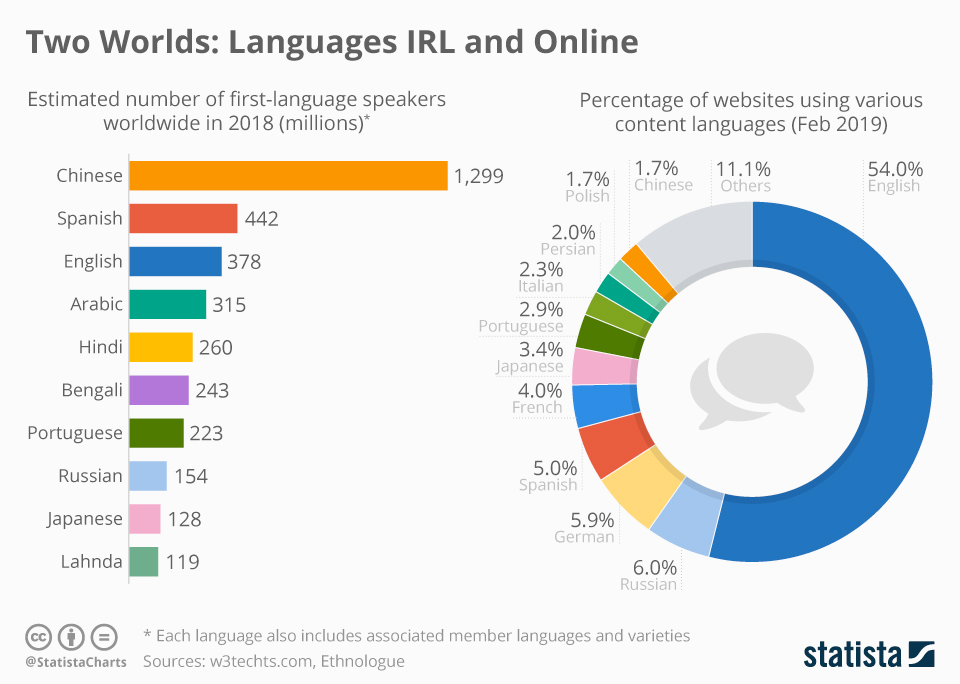
สาเหตุสำคัญที่ภาษาอังกฤษเหนือกว่าอยู่ที่ปริมาณและคุณภาพของข้อมูล ตัวอย่างเช่น ฐานข้อมูล Common Crawl ซึ่งเป็นแหล่งข้อมูลหลักที่ใช้ในการฝึก LLMs มีข้อมูลภาษาอังกฤษมากถึงราว 44% ขณะที่ไม่มีภาษาใดเกิน 6% นอกจากนี้ เว็บไซต์ทั่วโลกที่ตรวจสอบได้กว่า 49% ใช้ภาษาอังกฤษ แม้ว่าผู้พูดภาษาอังกฤษเป็นเจ้าของภาษาจะมีจำนวนน้อยกว่าภาษาจีนเสียอีก
ไม่เพียงเท่านั้น กระบวนการ reinforcement learning with human feedback (RLHF) ซึ่งใช้ปรับแต่งพฤติกรรมโมเดลก็มักดำเนินการโดยผู้ประเมินที่พูดภาษาอังกฤษ แนวทางความปลอดภัยและจริยธรรมที่ถูกออกแบบสำหรับโมเดลก็ล้วนสร้างขึ้นในบริบทภาษาอังกฤษ ทำให้โมเดลจำนวนมากไม่เพียงแต่ “เก่งภาษาอังกฤษ” แต่ยัง “คิดแบบภาษาอังกฤษ” โดยโครงสร้าง
ผลกระทบต่อผู้ใช้ภาษาท้องถิ่น
ความเหลื่อมล้ำทางภาษานี้ส่งผลโดยตรงต่อผู้ใช้ทั่วโลก
- ข้อจำกัดในการเข้าถึง – ผู้ใช้ที่ไม่ถนัดภาษาอังกฤษไม่สามารถเข้าถึงความสามารถเชิงลึกของ AI ได้เต็มที่
- คุณภาพการตอบสนองต่ำกว่า – แม้ถามด้วยภาษาแม่ โมเดลก็มักตีความผ่านกรอบภาษาอังกฤษก่อน ทำให้คำตอบแฝงสมมติฐานทางวัฒนธรรมแบบตะวันตก
- การขาดเทคนิคขั้นสูง – กลยุทธ์การเขียน prompt ที่ก้าวหน้า มักถูกเผยแพร่ในภาษาอังกฤษ ทำให้ผู้ใช้ภาษาอื่นเสียเปรียบ
สิ่งเหล่านี้ก่อให้เกิด “ช่องว่างทางดิจิทัล” รอบใหม่ ที่ไม่ได้ขึ้นอยู่กับการเข้าถึงอินเทอร์เน็ตหรืออุปกรณ์ แต่ขึ้นอยู่กับ ภาษา ที่เราพูดและเขียน

บทเรียนสำหรับประเทศไทย: ทำไมเราต้องมี LLM ภาษาไทย
เพื่อลดช่องว่างนี้ หลายประเทศในเอเชียได้พัฒนาโมเดลภาษาของตนเอง จีน ญี่ปุ่น และเกาหลีใต้ต่างมี LLMs ที่รองรับภาษาท้องถิ่น ในภูมิภาคอาเซียนก็มีการเคลื่อนไหวอย่างเข้มข้น รายงานของ Carnegie Endowment (2025) แสดงให้เห็นว่าประเทศในเอเชียตะวันออกเฉียงใต้เริ่มมี LLMs เป็นของตัวเองอย่างต่อเนื่อง
การมี LLM ภาษาไทยไม่เพียงเป็นเรื่องเทคนิค แต่ยังเป็นเรื่องของความมั่นคงทางวัฒนธรรมและข้อมูล หากประเทศไทยพึ่งพาเพียงโมเดลต่างประเทศ ย่อมมีความเสี่ยงที่จะสูญเสียอัตลักษณ์ทางภาษา รวมถึงการไหลออกของข้อมูลสำคัญสู่ต่างประเทศ
สำนักงานพัฒนาธุรกรรมทางอิเล็กทรอนิกส์ (ETDA) ได้ออกแนวทางการกำกับดูแล AI ของไทย โดยเสนอให้ใช้ “soft-law” หรือแนวปฏิบัติแทนการออกกฎหมายที่แข็งตัว เพื่อสร้างสมดุลระหว่างการสนับสนุนนวัตกรรมและการป้องกันความเสี่ยง แนวทางนี้เหมาะสมกับช่วงเริ่มต้นของการพัฒนา LLM ภาษาไทย ที่ยังต้องการความยืดหยุ่นและการสนับสนุนจากหลายภาคส่วน

บทสรุป
งานวิจัยระดับนานาชาติยืนยันตรงกันว่า ภาษาอังกฤษยังคงเป็นภาษาหลักในการทำงานของ LLMs ไม่ว่าจะเป็นในเชิงคุณภาพการตอบสนอง ความสามารถในการถ่ายทอดความรู้ หรือการตัดสินใจเชิงโครงสร้าง ข้อเท็จจริงนี้สะท้อนถึงความเหลื่อมล้ำทางภาษาในระบบ AI สมัยใหม่
สำหรับประเทศไทย แม้ในระยะสั้น ผู้ใช้ภาษาไทยอาจยังจำเป็นต้องใช้ prompt ภาษาอังกฤษเพื่อให้ได้ผลลัพธ์ที่ดีที่สุด แต่ในระยะยาว การพัฒนา LLM ภาษาไทยคือกลยุทธ์ที่ขาดไม่ได้ ไม่เพียงเพื่อความเท่าเทียมในการเข้าถึงเทคโนโลยี แต่เพื่อรักษาอธิปไตยทางข้อมูลและวัฒนธรรมด้วย
ในโลกที่ภาษาเป็นประตูสู่อนาคตของ AI คำถามสำคัญคือ: เราจะยอมให้อนาคตของเราเขียนด้วยภาษาอื่น หรือจะสร้าง AI ที่พูดภาษาเดียวกับเราได้อย่างแท้จริง?