
ในช่วงไม่กี่ปีที่ผ่านมา ปัญญาประดิษฐ์ขนาดใหญ่ (Large Language Models – LLMs) ได้เข้ามามีบทบาทอย่างมากในสังคม แต่ขณะเดียวกันก็กำลังเผชิญกับข้อจำกัดสำคัญสองประการ คือ การใช้พลังงานจำนวนมหาศาล และ การพึ่งพาทรัพยากรฮาร์ดแวร์ที่มีต้นทุนสูง เช่น GPU ของผู้ผลิตรายใหญ่ ปัญหาเหล่านี้ไม่เพียงกระทบต่อการพัฒนาเทคโนโลยี แต่ยังสร้างแรงกดดันต่อสิ่งแวดล้อมและความมั่นคงทางเทคโนโลยีของประเทศต่าง ๆ
ในเดือนกันยายน 2025 ทีมวิจัยจากสถาบันระบบอัตโนมัติ (Institute of Automation) แห่งสถาบันวิทยาศาสตร์จีน (CASIA) ได้เปิดตัว SpikingBrain-1.0 โมเดลภาษาใหม่ที่ออกแบบตามหลักการทำงานของสมองมนุษย์โดยตรง ถือเป็นการผสมผสานแนวคิดด้าน spiking neural networks (SNNs) เข้ากับการสร้าง LLM อย่างเป็นรูปธรรมครั้งแรก
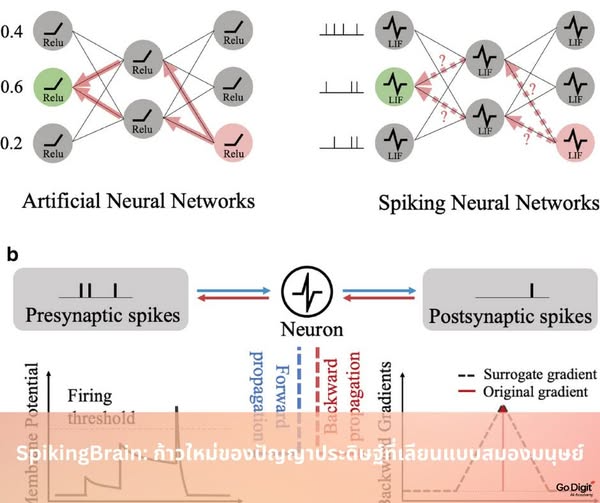
หลักการทำงาน: จาก Transformer สู่ Spiking Neural Networks
โมเดลภาษาแบบดั้งเดิม เช่น GPT หรือ Llama ใช้สถาปัตยกรรม Transformer ซึ่งต้องเปิดใช้งานนิวรอนจำนวนมากพร้อมกันในการประมวลผลหนึ่งครั้ง สิ่งนี้ทำให้การคำนวณสิ้นเปลืองพลังงานมหาศาล
SpikingBrain เลือกใช้แนวทางที่ต่างออกไป โดยอาศัยหลักการของ Spiking Neural Networks ที่จำลองการทำงานของสมองมนุษย์ เซลล์ประสาทในระบบนี้จะ “ยิงสัญญาณ” เฉพาะเมื่อมีสิ่งกระตุ้น (event-driven) ไม่ใช่ทำงานตลอดเวลา ทำให้ส่วนใหญ่ของเครือข่ายอยู่ในสถานะ “เงียบ” จนกว่าจะถึงเวลาที่จำเป็น แนวทางนี้นำไปสู่ การประหยัดพลังงานอย่างมีนัยสำคัญ ขณะที่ยังคงความสามารถในการประมวลผลข้อมูลขนาดใหญ่ได้
สถาปัตยกรรมของ SpikingBrain
SpikingBrain ถูกพัฒนาออกมาเป็น 2 ขนาดหลัก ได้แก่
SpikingBrain-7B: โมเดลเชิงเส้น (linear) ขนาด 7 พันล้านพารามิเตอร์ ใช้กลไก linear attention และ sliding-window attention เพื่อรองรับข้อมูลลำดับยาวได้อย่างมีประสิทธิภาพ
SpikingBrain-76B: โมเดลลูกผสม (hybrid) ขนาด 76 พันล้านพารามิเตอร์ ผสมผสานแนวคิด Mixture of Experts (MoE) กับกลไก spiking ทำให้เกิดความเป็น sparsity หลายระดับ ส่งผลให้ใช้พลังงานน้อยลงแต่ยังคงความสามารถในการเรียนรู้ที่ซับซ้อน
นอกจากนี้ยังมีการออกแบบระบบ adaptive threshold spiking ที่แปลงค่า activation เป็นสัญญาณตามเหตุการณ์เพื่อควบคุมพลังงานการคำนวณได้ดียิ่งขึ้น
ประสิทธิภาพที่เหนือกว่า
การทดสอบจากทีมวิจัยและรายงานหลายแหล่งเผยว่า SpikingBrain มีประสิทธิภาพที่น่าจับตา
ความเร็ว: สามารถตอบสนองต่อข้อความยาว 4 ล้าน token ได้เร็วกว่าโมเดล Transformer กว่า 100 เท่า และสร้าง token แรกจากบริบทยาว 1 ล้าน token ได้เร็วขึ้นถึง 26.5 เท่า
การประหยัดพลังงาน: ใช้พลังงานน้อยลงถึง 97.7% เมื่อเทียบกับการประมวลผลแบบ FP16 และ 85.2% เมื่อเทียบกับ INT8 ระดับ sparsity สูงถึง 69.15%
การเรียนรู้ด้วยข้อมูลที่น้อยกว่า: ใช้ข้อมูลเพียง 150 พันล้าน token (~2% ของที่โมเดลใกล้เคียงใช้) แต่ยังแสดงผลลัพธ์ใกล้เคียงกับโมเดลโอเพนซอร์สชื่อดัง เช่น Mistral-7B และ Llama3-8B
การทำงานบน CPU/Edge: การทดสอบบน CPU แสดงให้เห็นว่า SpikingBrain-7B ทำงานได้เร็วกว่า Llama3.2 ถึง 4–15 เท่าในงานที่มีความยาวอินพุต 64k–256k token
ความสำคัญด้านฮาร์ดแวร์: การพึ่งพาตนเองของจีน
อีกจุดที่ทำให้ SpikingBrain น่าจับตาคือการที่โมเดลถูกฝึกและรันบน MetaX GPU cluster ซึ่งพัฒนาโดยบริษัทจีนเองทั้งหมด โดยไม่ต้องพึ่งพา GPU ของ NVIDIA ที่กำลังถูกจำกัดการส่งออก เทคโนโลยีนี้จึงมีความหมายเชิงยุทธศาสตร์ในระดับชาติ เพราะสะท้อนความพยายามของจีนในการสร้าง ระบบนิเวศ AI ที่ควบคุมได้เอง
MetaX ยังได้ออกแบบเฟรมเวิร์กการฝึกเฉพาะ ไลบรารีออปเปอเรเตอร์ และกลไกการทำงานขนานให้สอดคล้องกับฮาร์ดแวร์ของตนเอง ช่วยให้การฝึกและการอนุมานของ SpikingBrain ทำได้อย่างเต็มประสิทธิภาพ
การประยุกต์ใช้งาน
SpikingBrain ถูกออกแบบให้เหมาะสมกับงานที่ต้องการการจัดการข้อความยาวมาก เช่น
การค้นหาข้อมูลใน เอกสารกฎหมายและเวชระเบียน
การจำลองวิทยาศาสตร์พลังงานสูง
การวิเคราะห์ลำดับพันธุกรรม (DNA sequence analysis)
ด้วยการใช้พลังงานที่ต่ำและรองรับการทำงานแบบเรียลไทม์ จึงมีศักยภาพที่จะนำไปสู่การใช้งานในระบบ edge computing และอุปกรณ์พกพา ตั้งแต่โดรน อุปกรณ์ IoT ไปจนถึงระบบสวมใส่ที่ไม่ต้องพึ่งการเชื่อมต่อกับศูนย์ข้อมูลขนาดใหญ่
ข้อจำกัดและความท้าทาย
แม้ผลลัพธ์ของ SpikingBrain จะดูน่าประทับใจ แต่ยังมีข้อจำกัดที่ต้องจับตามอง
ผลการวิจัยส่วนใหญ่ยังอยู่ในรูปแบบ preprint บน arXiv และยังไม่ผ่านการทบทวนโดยนักวิจัยภายนอก (peer review)
การอ้างถึงประสิทธิภาพที่สูงกว่าหลายเท่าอาจขึ้นอยู่กับเงื่อนไขการทดสอบที่เฉพาะเจาะจง
การใช้งานจริงอาจต้องการ ซอฟต์แวร์ เครื่องมือ และบุคลากรเฉพาะทาง ในการพัฒนาและบำรุงรักษา
การแข่งขันด้าน neuromorphic computing กำลังเข้มข้นทั่วโลก จึงต้องติดตามว่าทีมจีนจะรักษาความได้เปรียบนี้ไว้ได้หรือไม่
ผลกระทบในอนาคต
SpikingBrain อาจเป็นสัญญาณบ่งชี้ว่าอุตสาหกรรม AI กำลังเดินเข้าสู่ยุคใหม่ จากเดิมที่เน้น การขยายขนาดโมเดล (scaling law) ไปสู่การออกแบบที่ เน้นประสิทธิภาพ ความยั่งยืน และการเลียนแบบสมองมนุษย์
หากเทคโนโลยีนี้ได้รับการยืนยันในระดับสากลและใช้งานอย่างแพร่หลาย จะช่วยลดการใช้พลังงานของศูนย์ข้อมูลขนาดใหญ่ สร้างความเป็นอิสระด้านฮาร์ดแวร์ และอาจเป็นจุดเริ่มต้นของ AI ที่ใกล้เคียงการทำงานของสมองมนุษย์มากขึ้น
บทสรุป
SpikingBrain-1.0 ไม่เพียงเป็นความสำเร็จด้านวิศวกรรม แต่ยังเป็นการทดลองที่กล้าหาญในการนำหลักการของสมองมนุษย์มาใช้กับ AI อย่างเป็นรูปธรรม ผลงานนี้ชี้ให้เห็นถึงความเป็นไปได้ของการสร้างโมเดลที่ เร็วกว่า ประหยัดพลังงานกว่า และพึ่งพาทรัพยากรน้อยกว่า การออกแบบแบบเดิม
แม้ว่ายังมีคำถามและข้อท้าทายที่ต้องการคำตอบจากการวิจัยเพิ่มเติม แต่ SpikingBrain ได้แสดงให้เห็นว่าอนาคตของ AI อาจไม่ได้อยู่ที่การสร้างโมเดลที่ใหญ่ขึ้นเรื่อย ๆ หากแต่อยู่ที่การเข้าใจและเลียนแบบวิธีที่ธรรมชาติจัดการกับความฉลาดผ่านสมองมนุษย์